
We start off quickly looking at the notion of "database" and
consider the simple relational database model of tables with tuples (rows) and
attributes (columns). A popular way to design a database is through
ER diagrams, and we look at a sample diagram. I hope that you
won't get bogged down when we discuss the relational algebra, set
theoretic notions that the relational model is based upon. Though it is
important to have some basic understanding of the relational algebra,
in practice most users take advantage of a higher level language for
retrieving information from a database, and we look at SQL (Structured
Query Language) as a common example. Finally, we motivate the use
of Microsoft Access, a popular relational database system, and follow-on with
a detailed tutorial on how to use Access.
With a bit more precision, when we use the term database, we mean a logically coherent collection of related data with inherent meaning, built for a certain application, and representing a "mini-world". A database management system (DBMS) is software that allows databases to be defined, constructed, and manipulated.
Here we will very briefly consider the relational model with
Microsoft Access
as an example DBMS, as a background basis in understanding how java
can work with databases. For further details,
there are any number of good database textbooks.
When I first studied databases about ten years ago, I used perhaps the classic
text, C.J. Date's An Introduction to Database Systems (Addison-Wesley).
(Date was responsible for popularizing the now widely accepted relational
database model, based on E.F. Codd's 1968 defining work.)
I have also used Fundamentals of Database Systems by Ramez Elmasri
and Shamkant B. Navathe (Benjamins/Cummings) and M.Tamer Ozsu and Patrick
Valduriez's Principles of Distributed Database Systems (Prentice Hall).
There are three typical implementation models of databases: hierarchical, network, and relational. Each is based on the notion of data stored as a set of records (imagine a set of file cards, for example). Hierarchical (e.g., IMS) and network (e.g., IDMS) models are based on traversing data links to process a database; they are typically used for large mainframe systems and are not considered further here.
We focus on relational database management systems (RDBMSs). They have become popular, perhaps largely due to their simple data model:

Just as a side note, the notion of view can be useful. Imagine that a company maintains a database of its employees -- there might be a lot of attributes like age, salary, emergency contacts, appraisal, etc. There may be needs to look at the database for different applications serving different users. The company may need to make available demographic data, for example, to a governmental agency. Only some of the attributes need be supplied - and others ought not to so as to protect privacy. Different views can be provided into the same data; in a RDBMS, a view can be seen as yet another table.
Just a few words about design. How do you go about designing a database? It is useful to build a high level conceptual data model where we depict the entities that we are dealing with, their various attributes, and their relationships. An entity is some object with a real or conceptual existence in the world -- "tofu", "Advanced Java Class", "Folger Museum", "Elaine", "company", for example. An attribute is a property of an entity -- "address", "size", "mother", "age", for example. As mentioned above, a relational column is an attribute. A relationship defines roles in which entities work together -- "Bill WORKS-FOR Motorola", "jbs TEACHES advanced-java". RDBMSs represent relationships as tables. A side note for those already familiar with normalizing databases - ER design has been shown (Eugene Wong) to give relations in third normal form. Also, ER diagrams can be mapped not just to RDBMS, but also to the network and hierarchical models.
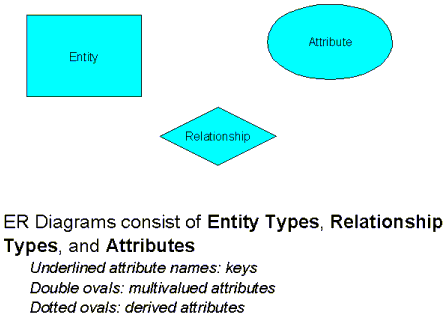
It is relatively straighforward to represent a database design in graphical
ER Diagrams, where rectangles represent entity types, diamonds relationship
types, and ovals attributes. Underlined attribute names represent keys.
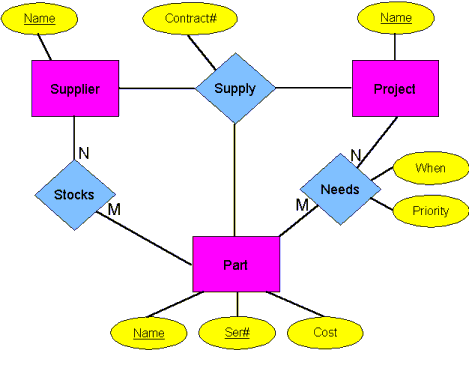
Here is an example ER diagram:
E.F. Codd's work that inspired RDBMSs was based on mathematical notions, so it is no surprise that the theory of database operations are based on set theory. If you are math-averse, don't be "scared" by this section; you can safely skim or skip it, but see if the Select and Project operators make sense, and review the Join diagram.
The Relational Algebra provides a collection of operations to manipulate relations. It supports the notion of a query, or request to retrieve information from a database. There are set operations:
jbs 010-00-1111 A32 A09 Multimedia Projects
jbs 010-00-1111 A32 A11 Software Reuse
jbs 010-00-1111 A32 A21 New Department
jbs 010-00-1111 A32 A32 Java Applications
jbs 010-00-1111 A32 B01 Accounting
wms 033-53-3902 A32 A09 Multimedia Projects
...
jbs 505-47-8901 A09 B01 Accounting
we select those records where Dept is A32.

Phew! Just a few more points. We have described the most general join, called a theta join, where the condition can be complex. Typically, the condition is simply testing if a set of attributes equal a set of values (att1 = val1 & att2 = val2 & ...); then we have an equijoin. (The next sentence is false. The previous sentence is true. Just seeing if you're with me!) Finally, a semijoin, also common in practice, is a subset of tuples of the first relation that participate in the join with the second relation; it is represented with a "bowtie" operator where the right-most vertical line is missing. In our example above, were it a semijoin, the result would just be the subset of Employee Table2 consisting of the first two records.
Still with me?! We skipped some additional operators like natural joins (really just a notational shortcut for equijoins), set division (very rarely used and rather awkward!), outer joins, outer unions, and aggregate functions (mathematical functions applied to values in a database - e.g., average age calculated from an age attribute, or count of records).
The basic message I hope that you got is that the relational algebra allows one in a set theoretic fashion to retrieve information from a database. As end users we would probably prefer to be less mathematical, and that's where the Relational Calculus comes in!
The Relational Calculus is a formal query language. Instead of having to write a sequence of relational algebra operations, we simply write a single declarative expression, describing the results that we want. This is somewhat akin to writing a program in C or java instead of assembler, or (in the spirit of real world examples!) telling the babysitter to call with any problems instead of detailing how to pick up the phone, dial numbers, etc.
The expressive power is identical to using relational algebra. Many commercial databases use a language like ... like ... (this is the keyword you were waiting for - sorry you had to wade so far!) SQL (finally!) -- Structured Query Language -- or even a language like QBE (Query by Example) or QUEL (similar to SQL and used for the INGRES RDBMS). A specific relational query language is said to be relationally complete if it can be used to express any query that the relational calculus supports.
There are two common ways of creating a relational calculus (both are based on First Order Predicate Calculus, or basic logical operators). In a Tuple Relational Calculus, variables range over tuples - i.e., variables can take on values of individual table rows. This is just what we want to do a routine query, such as selecting all food items (tuples) from a grocery store (table) where all the ingredients (specific attribute) are organic (value), say. In a Domain Relational Calculus, variables range over domain values of the attributes. This tends to be more complex, and variables are required for each distinct attribute.
But enough theory! In the remainder of the lesson, we'll
take a quick look at SQL and then conclude by looking at
some Microsoft Access (which uses SQL) screens.
Peanut butter and jelly break anybody?
SQL is both a Data Definition Language (DDL) and a Data Manipulation Language (DML). As a DDL, it allows a database administrator or database designer to define tables, create views, etc. As a DML, it allows an end user to retrieve information from tables. It came from an IBM Research project entitled "SEQUEL" where the intent was to create a structured English-like query language to interface to the early System R database system. Along with QUEL, SQL was the first high level declarative database language.
In this section, we will just give a few examples of SQL syntax to help suggest some familiarity with the style. For further reference, any number of books can be consulted. Also, SQL is widely used, and a quick search on the web came up with an excellent syntax reference, as well as a pretty good one and one that presents several examples to teach syntax.
In this example that follows, we create a table and insert two records. Note that attributes are positional and are specified in the same order in Create Table, unless a specific ordered attribute list is specified in the Insert Into statement (non-specified values are null).
Create Table Song
(Title varchar(20) not null,
Artist varchar(16) not null,
Album varchar(20),
Time char(5)
);
Insert Into Song
Values ("Roundabout", "Yes", "Fragile", "9:35");
Insert Into Song (Time, Artist, Title)
Values ("19:35", "Yes!", "I'll be the Roundabout");
Update Employee
Set Salary = Salary * 1.2
Where Evaluation > .85;
As you can see, SQL statements look a bit like English. The Delete statement (with a Where clause to specify conditions) removes selected tuples from a table.
The Select (no relation to the relational algebra operation) statement is probably the most widely used SQL statement, and it is used to retrieve data from a database. It has many options, and we will again just give a few examples to give a flavor.
The most basic Select statement on, say, a table called Bike, is
Select * From Bike;This just returns all tuples in the Bike table. We can be more selective and ask for, say, just the attributes Color, Serial Number, and Number of Gears:
Select Color, Serial Number, Number of Gears From Bike;This essentially applies the select and project relational operators to the table.
We can also apply conditions to be more selective. Maybe we want to look at our inventory of blue bikes with at least 10 gears and see which ones (identified by their serial numbers) have which number of gears, as well as their warehouse location:
Select Serial Number, Number of Gears, Location From Bike Where Color = "Blue" and Number of Gears >= 10;
We can even retrieve from multiple tables. For each blue bike, let's look at its serial number, location, manufacturer's name, and manufacturing date. We assume we have a table Manufacturer which has Serial Number as key and Date and Name as some attributes. To illustrate a point, let's assume that both tables have Name as an attribute; the value in the inventory on-hand Bike table is a vendor-supplied name, while the value of Name in the Manufacturer table is the name of the manufacturer.
Select Serial Number, Location, Manufacturer.Name, Date
From Bike, Manufacturer
Where Color = "Blue" And
Bike.Serial Number = Manufacturer.Serial Number;
(Note that we disambiguated Name by prefixing it with
the table name followed by a period.)
This example is like a relational algebra select-project-join
with equijoin condition on Color.
Let's look at the SQL for the join example we illustrated above. It is fairly straightforward:
Select * From Employee Table2, Department Table Where Dept = "A32";If we want to look at the distinct salaries we are paying to people in department A32, we can use the Distinct keyword:
Select Distinct Salary From Employee Where Dept = "A32";
These are just a few examples, but I hope that they show the power and
relative ease of SQL. It's hard to believe all the theory that we
very lightly touched on above lies beneath such straightforward declarative
syntax.
Access allows you to define and then store a set of queries and give these
queries names that are meaningful to you. Note the Tables
and Queries tabs in particular (Reports is useful
for generating hardcopy output, such as mailing labels).
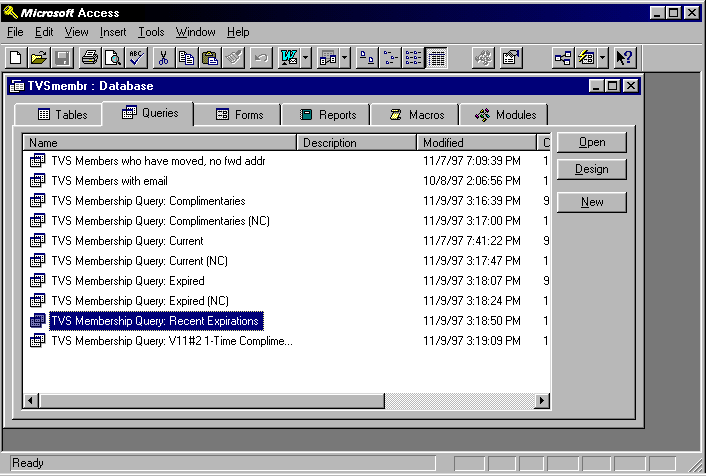
From this screen, if we select the Design button, we can
inspect and modify the query. Access makes it very easy to
select records from a database; the user doesn't have to write SQL at all.

If we View the SQL instead of the Query Design, we
get something less friendly looking:
SELECT DISTINCTROW [TVS Membership].LAST_NAME,
[TVS Membership].FIRST_NAME,
[TVS Membership].MEMBER_TYP,
[TVS Membership].ADDRESS1,
[TVS Membership].ADDRESS2,
[TVS Membership].CITY,
[TVS Membership].STATE,
[TVS Membership].ZIP,
[TVS Membership].EXPIRATION
FROM [TVS Membership]
WHERE (
( ([TVS Membership].MEMBER_TYP)<>"C" And
([TVS Membership].MEMBER_TYP)<>"1") AND
( ([TVS Membership].EXPIRATION)>Date()-60 And
([TVS Membership].EXPIRATION)< Date()
)
)
ORDER BY [TVS Membership].ZIP;
Finally, here we see how we can enter new records in the database.
We simply double click the name of our table and go to the last
entry, a pseudo- placeholder entry for a new record marked with an
asterisk in the left column. We just start typing in the field values,
tabbing field-to-field. Here you can see a new record being created
for Victor the Vegetarian.

This should give you a general idea of what Access looks like.
For more details,
I have put together a detailed
Access tutorial. It steps you through creating the Employee Table
we have been discussing, as well as retrieving data from that table.