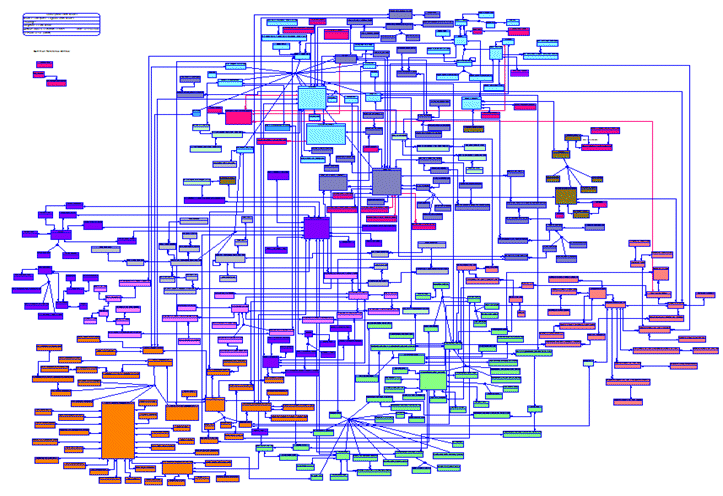
Data Warehouse Architectures
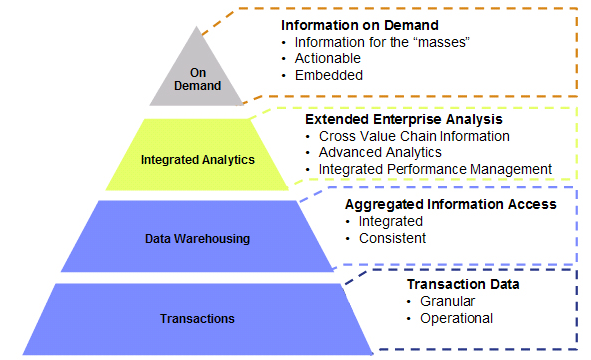
Analytics Layers as visualized by IBM
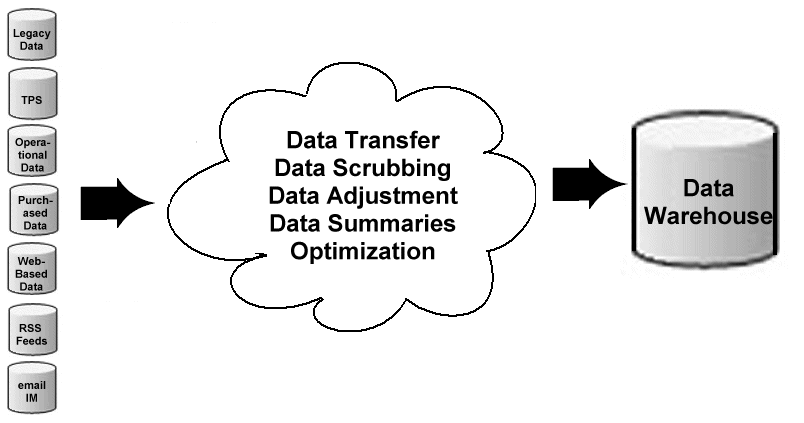
Tasks of a Data Warehouse as visualized by IBM
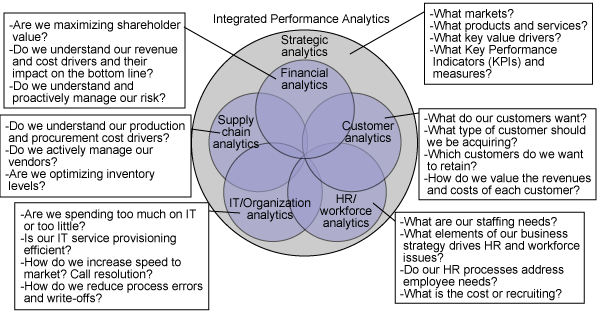
OLAP: Online Analytical Processing -- Analytical queries vs. transactions
- Data separate from applications
- Data separate from transaction processing systems
- Synonymous with drill down and pivot capabilities (looking at data from multiple perspectives)
- Slicing allows filtering of data (narrowing search)
- · Performance: data be accessed very rapidly without hurting TPS
- · Multiple Data Sources: internal, external and even desktop
- · Data Need to be Cleaned!
- · Data Need to be Adjusted!
An enterprise data model
Related Concepts:
- DOLAP: The desktop OLAP market resulted from the need for users to run business queries using relatively small data sets extracted from production systems. Most desktop OLAP systems were developed as extensions of production system report writers, while others were developed in the early days of client/server computing to take advantage of the power of the emerging (at that time) PC desktop. Desktop OLAP systems are popular and typically require relatively little IT investment to implement. They also provide highly mobile OLAP operations for users who may work remotely or travel extensively. However, most are limited to a single user and lack the ability to manage large data sets.
- MOLAP: The first generation of server-based multidimensional OLAP (MOLAP) solutions use multidimensional databases (MDDBs). The main advantage of an MDDB over an RDBMS is that an MDDB can provide information quickly since it is calculated and stored at the appropriate hierarchy level in advance. However, this limits the flexibility of the MDDB since the dimensions and aggregations are predefined. If a business analyst wants to examine a dimension that is not defined in the MDDB, a developer needs to define the dimension in the database and modify the routines used to locate and reformat the source data before an operator can load the dimension data.
- Another important operational consideration is that the data in the MDDB must be periodically updated to remain current. This update process needs to be scheduled and managed. In addition, the updates need to go through a data cleansing and validation process to ensure data consistency. Finally, an administrator needs to allocate time for creating indexes and aggregations, a task that can consume considerable time once the raw data has been loaded. (These requirements also apply if the company is building a data warehouse that is acting as a source for the MDDB.) Organizations typically need to invest significant resources in implementing MDDB systems and monitoring their daily operations. This complexity adds to implementation delays and costs, and requires significant IT involvement. This also results in the analyst, who is typically a business user, having a greater dependency on IT. Thus, one of the key benefits of this OLAP technology — the ability to analyze information without the use of IT professionals — may be significantly diminished.
- ROLAP: Relational OLAP (ROLAP) implementations are similar in functionality to MOLAP. However, these systems use an underlying RDBMS, rather than a specialized MDDB. This gives them better scalability since they are able to handle larger volumes of data than the MOLAP architectures. Also, ROLAP implementations typically have better drill-through because the detail data resides on the same database as the multidimensional data .
- The ROLAP environment is typically based on the use of a data structure known as a star or snowflake schema. Analogous to a virtual MDDB, a star or snowflake schema is a way of representing multidimensional data in a two-dimensional RDBMS. The data modeler builds a fact table, which is linked to multiple dimension tables. The dimension tables consist almost entirely of keys, such as location, time, and product, which point back to the detail records stored in the fact table. This type of data structure requires a great deal of initial planning and set up, and suffers from some of the same operational and flexibility concerns of MDDBs. Additionally, since the data structures are relational, SQL must be used to access the detail records. Therefore, the ROLAP engine must perform additional work to do comparisons, such as comparing the current quarter with this quarter last year. Again, IT must be heavily involved in defining, implementing, and maintaining the database. Furthermore, the ROLAP architecture often restricts the user from performing OLAP operations in a mobile environment.
- HOLAP: Some vendors provide the ability to access relational databases directly from an MDDB, giving rise to the concept of hybrid OLAP environments. This implements the concept of "drill through," which automatically generates SQL to retrieve detail data records for further analysis. This gives end users the perception they are drilling past the multidimensional database into the source database.
- The hybrid OLAP system combines the performance and functionality of the MDDB with the ability to access detail data, which provides greater value to some categories of users. However, these implementations are typically supported by a single vendor’s databases and are fairly complex to deploy and maintain. Additionally, they are typically somewhat restrictive in terms of their mobility.
Storing Data
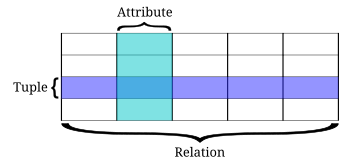
- Relational Database -- BUT data are stored in de-normalized form!
- Relational Structure: use tables to store data
- Use indices to connect data to form relationships of interest
- Use SQL to access data
- Often this is not sufficient to bring about the level of analysis necessary
- Wikipedia's discussion of relational databases
- Multidimensional Database -- often store aggregated or pre-computed data in Cubes
- Performance is usually good
- Wikipedia's discussion of multidimensional databases
- More about Multidimensional databases
- Client-based Files -- usually small or shadow systems
- Many vendors wish to discourage this
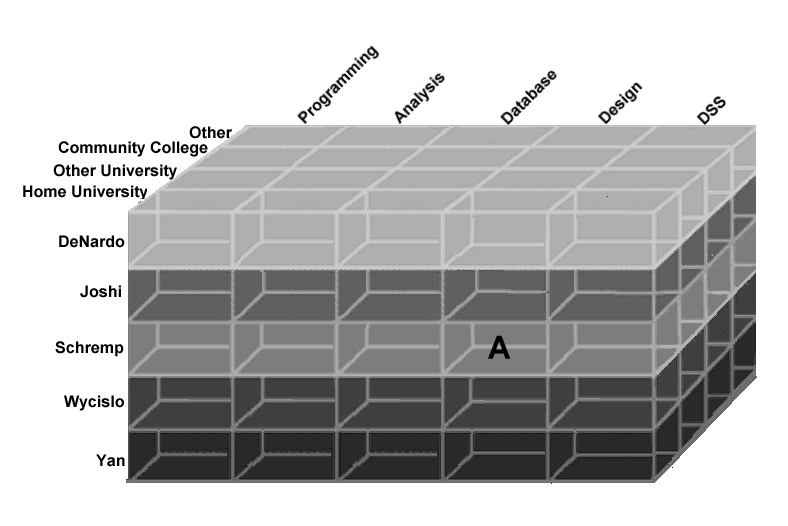
Products in each of those categories can be identified from this matrix.
Building cubes